
About me
Francisco Jesus Bacotich Baez
- Open to work
- Atlanta, GA, USA
- 24 years old

I am a passionate Data Engineering student, that enjoys technology in every expression of it. With 4 years of experience in developing different products I feel confident that at this point with the correct amount of patience and dedication, almost any problem that is presented to me can be mutated into actionable solutions.
Last update: 4/4/2024

My goal is to ensure efficient data storage, retrieval, and manipulation. I specialize in relational databases, particularly MySQL and PostgreSQL, as they offer robust solutions for structured data management.
- MySQL: Proficient in administering MySQL databases, including installation, configuration, and performance tuning. Experienced in designing relational schemas to optimize data storage and retrieval.
- PostgreSQL: Skilled in leveraging PostgreSQL’s advanced features such as table partitioning, JSONB data types, and full-text search capabilities. Proficient in implementing complex queries and stored procedures to manipulate data efficiently.
- Schema Design: Well-versed in designing normalized database schemas to minimize redundancy and maintain data integrity. Experienced in creating entity-relationship diagrams (ERDs) to visualize database structures and relationships.
- Query Optimization: Adept at writing efficient SQL queries using indexing, query optimization, and execution plan analysis. Experienced in diagnosing and resolving performance bottlenecks to ensure optimal query performance.
- Data Security: Knowledgeable about implementing security measures such as role-based access control (RBAC), encryption, and auditing to protect sensitive data stored in relational databases.
Example Project: Database Migration and Optimization
- Migrated a legacy database from MySQL to PostgreSQL, reducing query response times by 30% through query optimization and index tuning.
- Designed and implemented a relational schema for a customer relationship management (CRM) system, improving data accessibility and integrity for sales and marketing teams.
I am dedicated to ensuring data integrity, quality, and compliance through effective data governance practices and meticulous data modeling techniques. By implementing robust data governance frameworks and creating well-designed data models, I ensure that data assets are managed responsibly and utilized effectively to drive business value.
Data Governance:
- Policy Development: Developed data governance policies and procedures to define roles, responsibilities, and standards for data management.
- Compliance Management: Implemented mechanisms to ensure compliance with data protection regulations such as GDPR and HIPAA, including data anonymization and consent management.
- Data Quality Management: Established data quality metrics and processes to monitor, measure, and improve data quality across the organization.
- Metadata Management: Implemented metadata management solutions to catalog and track data lineage, ensuring transparency and traceability of data assets.
Data Modeling:
- Conceptual and Logical Modeling: Created conceptual and logical data models to represent business requirements and define data structures and relationships.
- Normalization and Denormalization: Applied normalization techniques to eliminate data redundancy and improve data integrity, and denormalization techniques to optimize query performance.
- Dimensional Modeling: Designed dimensional models such as star schemas and snowflake schemas for data warehousing applications, enabling efficient analysis and reporting.
- Tool Proficiency: Proficient in using data modeling tools such as Lucidchart to create and maintain data models.
Example Project: CRM System Implementation
- Developed data governance policies and procedures for the CRM system project, defining data ownership, access controls, and data quality standards.
- Created conceptual and logical data models to represent customer entities, attributes, and relationships, ensuring alignment with business requirements.
- Implemented metadata management mechanisms to track the lineage of customer data from acquisition to analysis, enhancing transparency and accountability.
With a focus on scalability, reliability, and efficiency, I ensure that data is processed and transformed accurately to meet business requirements.
- Data Ingestion: Proficient in configuring data ingestion mechanisms to extract data from various sources, including databases, APIs, logs, and file systems. Experienced in using tools like Apache Kafka and AWS Kinesis for real-time and batch data ingestion.
- Data Processing: Skilled in designing data processing workflows using distributed computing frameworks such as Apache Spark. Capable of handling large volumes of data and implementing complex data transformations to derive meaningful insights.
- Data Transformation: Experienced in transforming and enriching data using techniques such as data cleansing, normalization, and aggregation. Proficient in writing custom data transformation logic using programming languages like Python.
- Data Storage: Knowledgeable about different storage options for intermediate and final data storage, including data lakes, data warehouses, and NoSQL databases. Skilled in selecting the appropriate storage solution based on data requirements and access patterns.
- Orchestration and Monitoring: Proficient in orchestrating and scheduling data pipeline workflows using tools like Apache Airflow or Kubernetes. Experienced in implementing monitoring and alerting systems to track pipeline performance and ensure data quality and reliability.
Example Project: Real-time Data Streaming Pipeline
- Designed and implemented a real-time data streaming pipeline using Apache Kafka and Apache Spark Streaming to process and analyze clickstream data for personalized recommendations.
- Orchestrated the pipeline using Apache Airflow, scheduling data ingestion, processing, and visualization tasks to ensure timely and accurate delivery of insights to stakeholders.
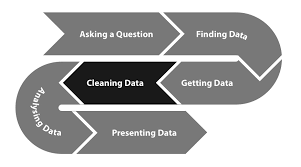
Transforming complex data into insightful visualizations that drive decision-making and enhance understanding. Leveraging a combination of tools and techniques to craft compelling visual narratives that illuminate trends, patterns, and insights hidden within the data.
Key Skills and Tools:
- Data Extraction: Proficient in extracting data from various sources, including APIs, databases, and files, to obtain raw data for analysis.
- Data Transformation: Skilled in transforming raw data using tools like pandas, numpy, and Jupyter Notebooks to prepare it for visualization.
- Visualization Tools: Experienced in creating visualizations using matplotlib, seaborn, and Tableau to effectively communicate data-driven insights.
- Graph Generation: Capable of generating a wide range of graphs, including bar charts, line plots, scatter plots, and heatmaps, to showcase data patterns and trends.
- Interactive Visualizations: Proficient in creating interactive visualizations using tools like Tableau, enhancing user engagement and exploration of data.
- Dashboard Creation: Experienced in designing and developing dashboards to provide a comprehensive view of data and facilitate decision-making.
Example Project: UFC Analysis
- Data Extraction: Retrieved UFC fight data from a Kaggle dataset and supplemented it with additional data from the UFC API to enrich the analysis.
- Data Transformation: Cleaned and transformed the raw data using pandas and numpy to prepare it for visualization.
- Graph Generation: Created a variety of graphs using matplotlib and seaborn, including bar charts to compare fighter statistics, line plots to track fighter performance over time, and heatmaps to visualize fight outcomes.
- Tableau Visualization: Developed interactive visualizations in Tableau to explore fighter statistics, fight outcomes, and trends in UFC data.
- Insightful Visualization: Presented key findings and insights from the analysis through visually appealing and informative graphs and dashboards.
I am actively pursuing certification in AWS Cloud Practitioner, demonstrating my commitment to mastering cloud computing concepts and technologies. With a focus on AWS, I am equipped to leverage cloud services to build scalable, secure, and cost-effective data solutions.
- Fundamentals of AWS: Mastery of foundational AWS concepts, including the AWS Shared Responsibility Model, AWS global infrastructure, and basic AWS services like EC2, S3, and IAM.
- Infrastructure as a Service (IaaS): Understanding of IaaS principles, where cloud providers deliver virtualized computing resources over the internet, such as virtual machines, storage, and networking.
- Cloud Security: Proficiency in implementing security best practices, such as configuring IAM policies, enabling encryption at rest and in transit, and implementing network security controls.
- Cost Management: Ability to analyze and optimize AWS costs using tools like AWS Cost Explorer, Trusted Advisor, and Budgets, and implementing cost-effective architectural solutions.
- AWS Management Tools: Familiarity with AWS management tools like AWS Management Console, AWS CLI, and AWS SDKs for automating infrastructure provisioning, deployment, and management tasks.
Example Project: AWS Cloud Practitioner Certification Preparation
- Hands-On Experience: Utilized AWS Free Tier to gain practical experience with core AWS services, such as EC2, S3, RDS, and IAM, through hands-on labs and exercises.
- Conceptual Understanding: Studied AWS whitepapers, documentation, and online courses to deepen understanding of AWS cloud concepts, architecture, and best practices.
- Practice Exams: Completed practice exams and quizzes to assess readiness for the AWS Cloud Practitioner certification exam and identify areas for further study and improvement.
- Real-World Scenarios: Applied AWS concepts and skills to real-world scenarios and projects, such as deploying a web application on AWS using EC2 and S3, and implementing security and cost optimization measures.
- Continuous Learning: Engaged with AWS community forums, user groups, and events to stay updated on the latest AWS developments, best practices, and use cases.
As a data engineer, I leverage a combination of programming languages and big data technologies to process and analyze large volumes of data efficiently. My proficiency in Python and SQL enables me to tackle various data.
Programming Languages:
- Python: Utilized Python extensively for data cleaning, transformation, and analysis tasks using libraries such as pandas, NumPy, and matplotlib.
- SQL: Leveraged SQL for querying, manipulating, and aggregating data in relational databases, optimizing performance using techniques such as indexing and query optimization.
Big Data:
- Cloud Services: While preparing for the AWS Cloud Practitioner certification, I gained exposure to cloud-based big data services such as Amazon EMR (Elastic MapReduce) and Amazon Redshift. Although my focus was primarily on understanding cloud concepts and services, this experience provided me with insights into big data processing workflows and architectures.
Example Project:
- Data Processing Pipeline: Developed a data processing pipeline to analyze customer behavior data from an e-commerce platform.
- Used Python to ingest raw data from various sources and perform data cleaning and preprocessing tasks.
- Utilized SQL to query and aggregate data in a relational database to generate insights into customer purchase patterns.
- While preparing for the AWS Cloud Practitioner certification, gained awareness of cloud-based big data services like Amazon EMR, which could potentially be integrated into the pipeline for scalable data processing.
I have extensive experience working with Git in various data environments, contributing to streamlined processes and collaborative projects.
Git allows data engineers to track changes to their code, configurations, and data pipelines over time. This ensures that all modifications are documented, reversible, and attributable, facilitating collaboration and reducing the risk of errors.
Application of Git in Professional Experience
Tech Support at XyTech:
- Used Git to track changes to PowerShell scripts for the dynamic file classification system. Each script modification was documented, allowing for easy rollback in case of errors or undesired outcomes.
- Leveraged Git for managing SCCM configurations, enabling team members to collaborate on deployment scripts and ensuring consistency across installations.
XyTech Website Design:
- Employed Git for version control of Flask and Django APIs development. Team members collaborated on feature branches, merged their changes, and resolved conflicts efficiently, ensuring smooth progress of the project.
- Maintained a Git repository for database schema changes and migrations, enabling data engineers to track and manage changes to the database structure over time.
GameJam Project:
- Utilized Git for version control of the game codebase, allowing team members to work on different aspects of the game concurrently. Branches were used to develop new features, while pull requests facilitated code reviews and integration into the main codebase.
- Iterative Development: I excel in breaking down complex data engineering tasks into manageable iterations, allowing for incremental development and frequent feedback loops.
- Collaboration and Communication: I thrive in cross-functional teams, fostering open communication and collaboration with stakeholders to ensure alignment on project goals and requirements.
- Adaptation and Continuous Improvement: I embrace change and uncertainty, leveraging retrospective feedback to refine processes and practices for continuous improvement.
- Delivering Value: I prioritize data engineering tasks based on business value and user needs, focusing on delivering high-priority features early to maximize value.
- Continuous Integration and Deployment: I advocate for automated testing and CI/CD pipelines to ensure data quality and accelerate the delivery of data solutions.
As I pursue my path as a data engineer, I recognize the importance of developing soft skills to complement my technical expertise. Two top recommendations are “Emotional Intelligence 2.0” by Travis Bradberry and Jean Greaves, which offers insights into emotional intelligence and its impact on success, and “How to Win Friends and Influence People” by Dale Carnegie, a classic guide to effective communication and interpersonal skills. These resources provide practical strategies and real-world examples to help me cultivate the qualities of a good person with a positive spirit, both in my career and in life.
Curiosity:
A good data engineer is fueled by curiosity, always eager to explore new datasets, technologies, and problem-solving approaches. Like a detective piecing together clues, they thrive on uncovering insights hidden within the data.
Creativity:
Data engineering is as much art as it is science. A dash of creativity allows data engineers to think outside the box, finding innovative solutions to complex data challenges and transforming raw data into meaningful insights.
Collaboration:
Data engineering is a team sport, requiring collaboration with data scientists, analysts, and stakeholders. A good data engineer is a team player, adept at communicating ideas, sharing knowledge, and working together towards common goals.
Adaptability:
In the ever-evolving world of data, flexibility is key. A good data engineer embraces change, adapting quickly to new technologies, methodologies, and project requirements with a sense of adventure and resilience.
Attention to Detail:
Data engineering is all about the details. Whether it’s writing code, designing data pipelines, or analyzing datasets, a good data engineer pays close attention to the details, ensuring accuracy, reliability, and quality in every aspect of their work.
Problem-Solving:
At its core, data engineering is about solving problems. Whether it’s optimizing query performance, troubleshooting pipeline failures, or designing scalable architectures, a good data engineer approaches challenges with creativity, logic, and determination.
Communication:
Effective communication is essential for success in data engineering. A good data engineer is able to translate complex technical concepts into plain language, bridging the gap between data and decision-makers with clarity, confidence, and charisma.
Sense of Humor:
Last but not least, a sense of humor goes a long way in data engineering. Whether it’s debugging a tricky code issue or wrangling messy data, a good data engineer approaches challenges with a smile, finding joy in the journey and laughter in the process.
With these soft skills in their toolkit, a data engineer is not only technically proficient but also a valuable team member, problem solver, and all-around data superhero!
Skills and Experience



- -Explore a dataset as fast as possible
- - Establishing secure and stable connection
- -Transform and model data to showcase KPI's regarding the topic of the dataset
- -Set a CRON task or orchestrate it with Airflow to automate data renewal

- -Used Route 53 to host domain.
- -Created a WP instance in LightSail
- -Learnt relevance of DNS management

- -Create a data lake architecture on AWS.
- -AWS S3 bucket as the central storage.
- -Upload sample datasets to the S3 bucket.
- -Use AWS Glue to crawl and catalog the data stored in the bucket.
- - Utilize Amazon Athena to query the data
- - Explore and analyze using Athena.

- -Storing encrypted data into SFTP
- -Creation of dimensional model
- -Pull data and load into Warehouse



- -Connected to the League of Legends API
- - Automated credentials renewal
- -Transformed data with Jupyter Notebooks
- - Implemented a small application to visualize the data
- -Godot as game engine motor
- - GD Script, git and Linux
- - Asperite and Kritta for the Art
- - Implemented team work methodologies

Education
Passed the exam on May 28.
Certified Hardvard course on Machine learning fundamentals with several algorithms implementations with hand on projects.
- Data modeling, querying, and management of large datasets. Transaction management. RDBS
- Securing P.I.I , user management/ACL’s , password authentication and securing connections with SSL.
- HTML ,Css ,GitHub , JavaScript , Bootstrap , SQL( PhPMyadmin & SQLWorkbench) and Python.
Topics of Personal Research for Educational purposes
- Kimballs Data Warehousing
- Docker
- Kubernetes
- Apache Spark
- “Emotional Intelligence 2.0” by Travis Bradberry and Jean Greaves
- “How to Win Friends and Influence People” by Dale Carnegie
Contact me at anytime!
I am actively looking for an opportunity whether it is as a Data Engineer, Analyst or Software Developer. Feel free to consult with no commitment.